Scientific progress requires measurement, especially when working with a complex system such as the economy or the human body. For example, our understanding of the relationship between cholesterol and human health continues to evolve, but it has only gotten to the point where we debate the merits of “good” cholesterol and “bad” cholesterol via a century of investigation and the development of measurement techniques. Similarly, although in a very different field, professional sports teams increasingly develop new, quantitative metrics of player performance in order to optimize team performance — as described by the book and movie “Moneyball.”
Good governance also can develop over time through careful measurement combined with scientific inquiry. To that end, I developed (along with my colleague, George Mason University economics professor Omar Al-Ubaydli) a new set of metrics of federal regulation called RegData.
{mosads}RegData offers novel metrics of an important input in our economy — federal regulation — and takes the first step in using a “Moneyball” approach to improving the regulatory system. This tool creates statistics based on the actual text in federal regulation, and these statistics can be used by researchers to create a better understanding of the causes and consequences of regulation. This week, a new version — RegData 2.0 — will be available for use, and it’s no longer just for researchers. RegData 2.0 can provide insights on the regulatory climate for anyone with a more than casual interest in regulations and public policy.
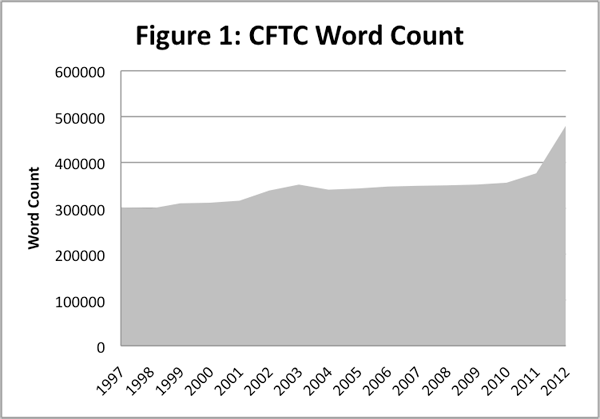
RegData 2.0 relies on custom-made text analysis software. With this software, federal regulatory text, as published annually in the Code of Federal Regulations (CFR), can be searched for different sets of key words. Moreover, the regulatory text can be divided up according to the regulator that created it, allowing the creation of regulator-specific quantifications of regulation. Two of RegData’s regulator-specific measurements are word counts and restriction counts. Word counts are what you imagine — the total number of words contained in a regulator’s text. Figure 1 below was created with data given here, and shows word count data for the Commodity Futures Trading Commission (CFTC) — the regulator in charge of futures and options markets. From 1997 to 2010, the CFTC’s regulatory text grew from 302,087 to 355,842 words. Years 2011 and 2012, however, saw a precipitous growth in regulation from CFTC, with the word count reaching 480,544 in 2012. This is most likely the result of new regulations caused by the Dodd-Frank Act of 2010.
RegData also permits the examination of restrictions. Restrictions are words that create binding legal obligations to engage in some activity or prohibition from doing so. Lawyers will recognize these restrictions — they are words like “shall,” “must,” and “may not.” Just as regulators differ in terms of how much text they produce, some regulators’ text may be more restrictive than others’. A RegData user can look at restriction data for entire departments, such as the Department of Transportation, or for smaller units within departments. RegData defines a regulator according to the Office of Management and Budget (OMB) MAX budget system, with the exception of the Environmental Protection Agency (EPA). The EPA (which is treated as one single regulator by OMB MAX) was divided into different agencies according to the names of the chapters of regulatory text EPA publishes, such as “Air Programs,” “Water Programs,” and “Pesticide Programs.” Figure 2 shows the 10 regulators that published the most restrictions in 2012. These 10 regulators accounted for about 31 percent of all restrictions published in the CFR in 2012.
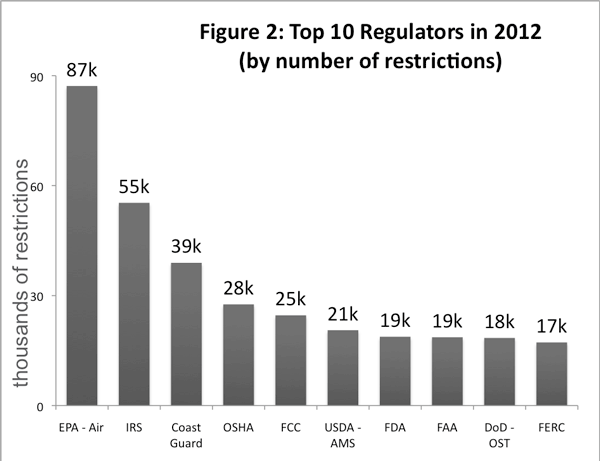
Source: Regdata.mercatus.org. Accessed Aug. 18, 2014.
Produced by Patrick McLaughlin and Rizqi Rachmat, Mercatus Center at George Mason University.
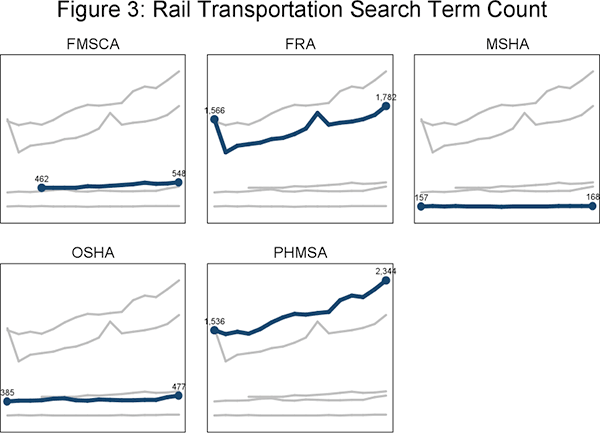
Perhaps the most innovative feature of RegData is its industry-specific measurements of regulation. Using search terms that are derived from industry descriptions given in the North American Industry Classification System, RegData can paint a picture of which industries are mentioned most often in regulatory text and by which regulator, as well as how that changes over time. For example, rail transportation is a major industry in the United States. RegData offers data on how often rail transportation-related search terms were found each year in the regulatory text of all federal regulators. Figure 3 offers a sample of just five of these regulators. Each of these series spans 1997 to 2012, with the exception of FMSCA — an agency that did not exist until the year 2000. It is not surprising to see the Federal Railroad Administration (FRA) mention railroads relatively often. But perhaps it is informative to learn that the Pipelines and Hazardous Materials Safety Administration (PHMSA) actually mentions them even more.
As with all exercises in measurement, RegData is not perfect. There are other ways that restrictions can be created, for example, than those indicated by words like “shall” and “must.” We also don’t know the object of the restriction, or its severity. Similarly, there are sections of regulatory text that apply to specific industries without using any of RegData’s industry-specific search terms.
Nonetheless, some of the largest gains in research come from the creation of new data and measurement techniques. Nate Silver compares new data’s first pass to “the way a vacuum’s first sweep of the living-room floor picks up a lot more dust and dirt than the second and third attempts.” The questions are: How much signal is RegData picking up, and how much noise? The answer will be told as researchers use the database to delve into questions such as whether and how regulation affects labor productivity, whether lobbying affects regulatory production, and how long-term regulatory trends might play into economic growth patterns. In turn, policymakers can learn from this research and hopefully improve future choices according to what we learn.
McLaughlin is a senior research fellow with the Mercatus Center at George Mason University.